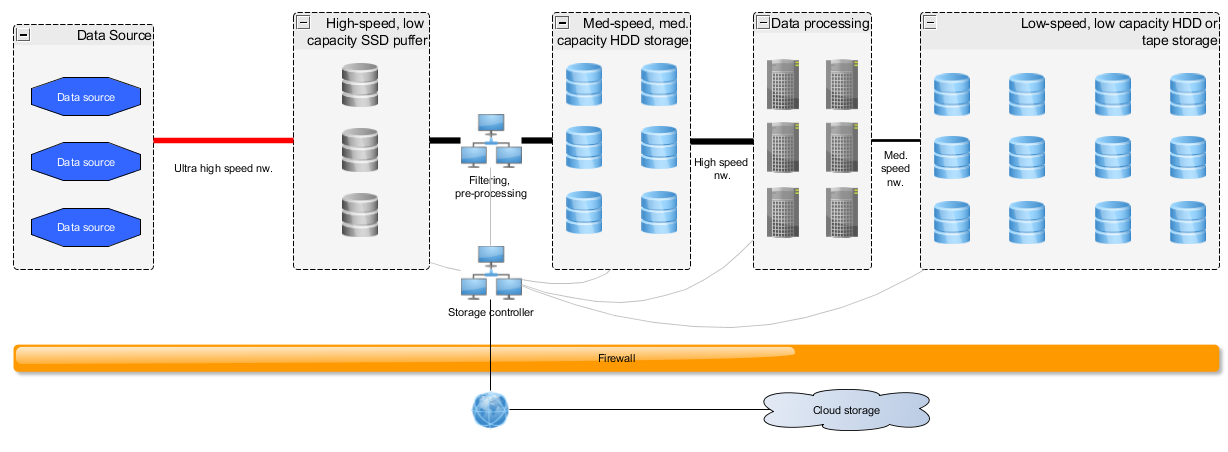
The article details an exemplary setup for a multi-tiered data warehouse and processing facility using Hadoop and batch type of data analysis
Requirements in brief:
- High peaks on data acquisition (e.g. financial transactions of yearly festivals, R&D facility with images or videos flowing in only at the time of experimenting)
- Velocity is high at peak times, Gigabytes / second for short time (max. few hours / day)
- Data to be fastly accessed for data processing for some weeks after acquisition
- High volume of data to be stored for long-time
- Data to be accessed some years after acquisition, access can be delayed by days after request
The below setup details 3 tiers:
- Tier:
- Hadoop data warehouse working with fast storage and fast network to cache raw data acquired right after an event of data generation
- Tier:
- Hadoop data processing facility working with medium speed storage and medium speed network to store and process raw data
- Hadoop data warehouse facility working with medium speed storage and medium speed network to store processed data for relatively fast access (analysis, visualization, post-processing, re-processing)
- Tier
- Hadoop data warehouse working with slow storage and slow network to store processed and raw data acquired some months ago
- On request data is moved from 3rd tier to 2nd tier